让不懂建站的用户快速建站,让会建站的提高建站效率!

专题:DeepSeek为何能转化全球AI圈

【导读】DeepSeek一天能赚若干钱?官方俄顷揭秘!潞晨科技暂停DeepSeek API做事
中国基金报记者 泰勒
天下好,沿路温雅一下对于DeepSeek的最新音书!
DeepSeek初次闪现:表面本钱利润率545%
当阛阓觉得DeepSeek的开源周内容发布结束之后,3月1日,DeepSeek晓谕了“One More Thing”,俄顷揭秘V3/R1推理系統,公开了大边界部署本钱和收益。
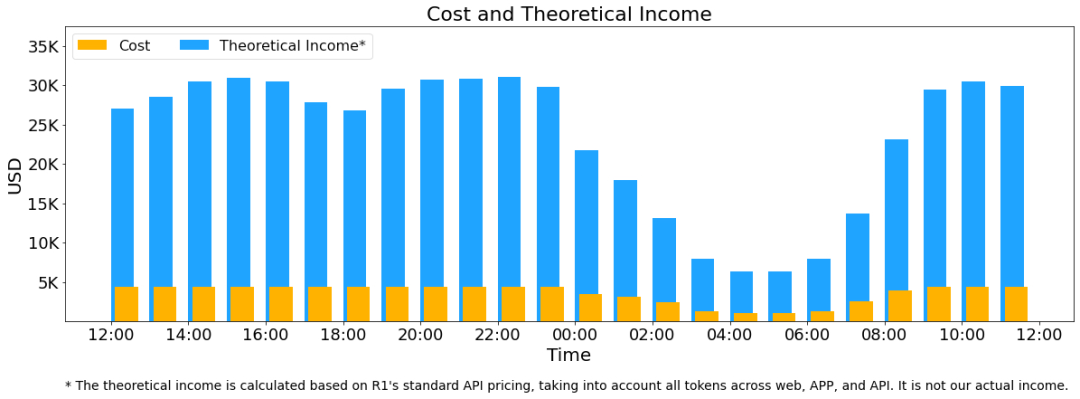
字据《DeepSeek-V3/R1推理系统概览》的著述,假设GPU租出本钱为2好意思元/小时,总本钱为87072好意思元/天;淌若统统tokens全部按照DeepSeek R1的订价计较,表面上一天的总收入为562027好意思元/天,本钱利润率为545%。
据官方闪现,DeepSeek-V3/R1推理系统的优化指标是:更大的朦拢,更低的延伸。
为了已毕这两个指标,DeepSeek使用大边界跨节点民众并行(Expert Parallelism / EP)。最初EP使得batch size大大加多,从而提升GPU矩阵乘法的遵循,提升朦拢。其次EP使得民众分散在不同的GPU上,每个 GPU 只需要计较很少的民众(因此更少的访存需求),从而缩小延伸。
但EP同期也加多了系统的复杂性。复杂性主要体当今两个方面:
EP引入跨节点的传输。为了优化朦拢,需要联想相宜的计较经由使得传输和计较不错同步进行。
EP触及多个节点,因此自然需要Data Parallelism(DP),不同的DP之间需要进行负载平衡。
因此,DeepSeek先容了怎么使用EP增大batch size,怎么逃避传输的耗时,怎么进行负载平衡。
大边界跨节点民众并行(Expert Parallelism / EP)
由于DeepSeek-V3/R1的民众数目广大,况兼每层256个民众中仅激活其中8个。模子的高度寥落性决定了必须接纳很大的overall batch size,身手给每个民众提供饱和的expert batch size,从良友毕更大的朦拢、更低的延时。需要大边界跨节点民众并行(Expert Parallelism / EP)。
接纳多机多卡间的民众并行政策来达到以下倡导:
Prefill:路由民众EP32、MLA和分享民众DP32,一个部署单位是4节点,32个冗余路由民众,每张卡9个路由民众和1个分享民众。
Decode:路由民众EP144、MLA和分享民众DP144,一个部署单位是18 节点,32个冗余路由民众,每张卡2个路由民众和1个分享民众。
计较通讯相同
多机多卡的民众并行会引入相比大的通讯支出,是以使用了双batch相同来遮蔽通讯支出,提升合座朦拢。
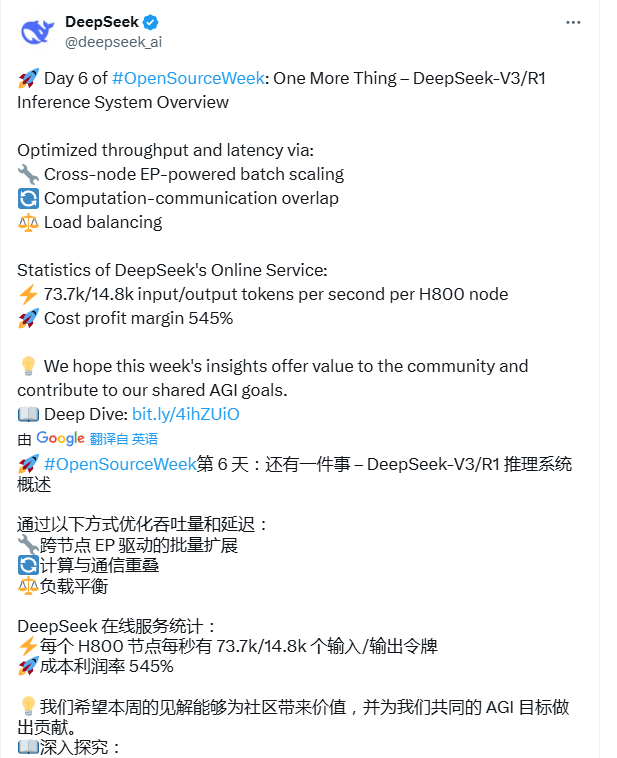
对于prefill阶段,两个batch的计较和通讯交错进行,一个batch在进行计较的时候不错去遮蔽另一个batch的通讯支出;
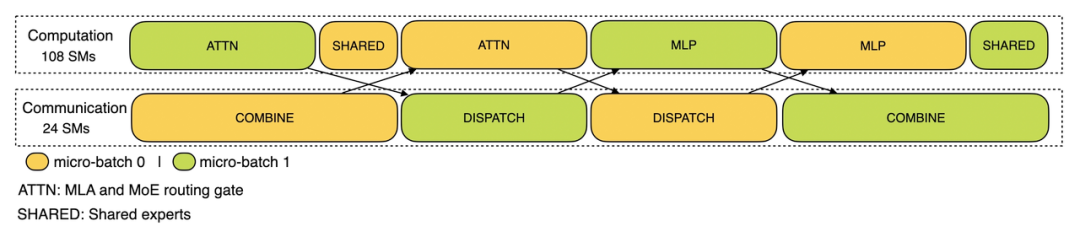
对于decode阶段,不同阶段的推论期间有所诀别,是以把attention部分拆成了两个stage,合计5个stage的活水线来已毕计较和通讯的相同。
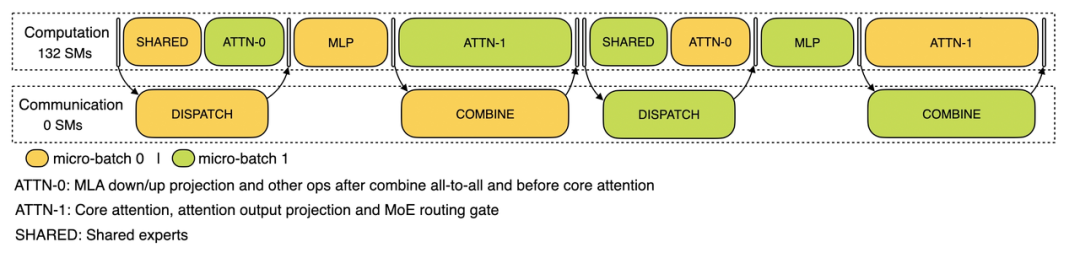
尽可能地负载平衡
由于接纳了很大边界的并行(包括数据并行和民众并行),淌若某个GPU的计较或通讯负载过重,将成为性能瓶颈,拖慢通盘系统;同期其他GPU因为恭候而空转,酿成合座应用率下落。因此需要尽可能地为每个GPU分派平衡的计较负载、通讯负载。
PrefillLoadBalancer
中枢问题:不同数据并行(DP)实例上的苦求个数、长度不同,导致core-attention计较量、dispatch发送量也不同。
优化指标:各GPU的计较量尽量调换(core-attention计较负载平衡)、输入的token数目也尽量调换(dispatch发送量负载平衡),幸免部分GPU处理期间过长。
DecodeLoadBalancer
中枢问题:不同数据并行(DP)实例上的苦求数目、长度不同,导致core-attention计较量(与KVCache占用量关系)、dispatch发送量不同。
优化指标:各GPU的KVCache占用量尽量调换(core-attention计较负载平衡)、苦求数目尽量调换(dispatch发送量负载平衡)。
Expert-ParallelLoadBalancer
中枢问题:对于给定MoE模子,存在一些自然的高负载民众(expert),导致不同GPU的民众计较负载不平衡。
优化指标:每个GPU上的民众计较量平衡(即最小化统统GPU的dispatch接纳量的最大值)。
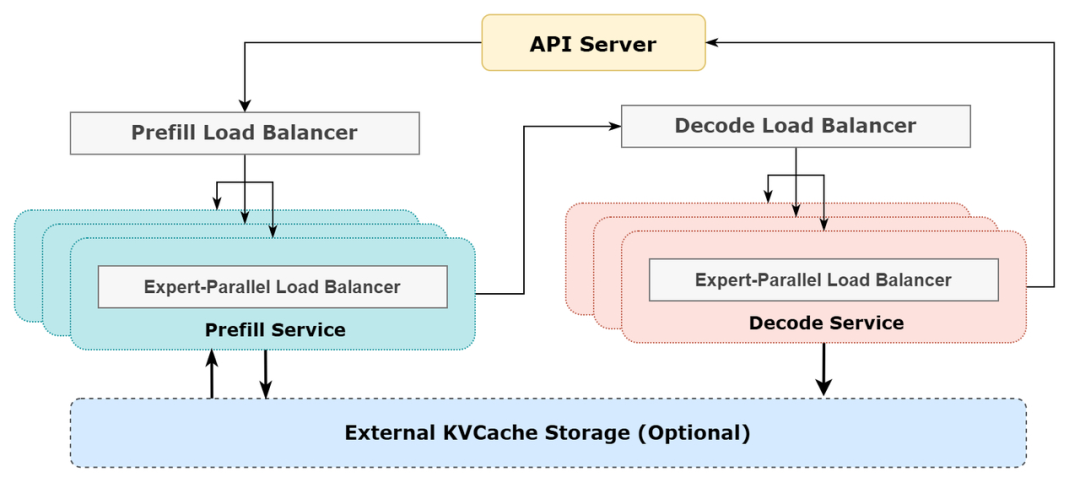
线上系统的实质统计数据
DeepSeekV3和R1的统统做事均使用H800GPU,使用和查考一致的精度,即矩阵计较和dispatch传输接纳和查考一致的FP8要领,core-attention计较和combine传输接纳和查考一致的BF16,最猛进度保证了做事成果。
另外,由于白昼的做事负荷高,晚上的做事负荷低,因此已毕了一套机制,在白昼负荷高的时候,用统统节点部署推理做事。晚上负荷低的时候,减少推理节点,以用来作念相干和查考。在最近的24小时里(北京期间2025/02/27 12:00至2025/02/28 12:00),DeepSeek-V3和R1推理做事占用节点总和,峰值占用为278个节点,平均占用226.75个节点(每个节点为8个H800GPU)。假设GPU租出本钱为2好意思金/小时,总本钱为87072好意思元/天。
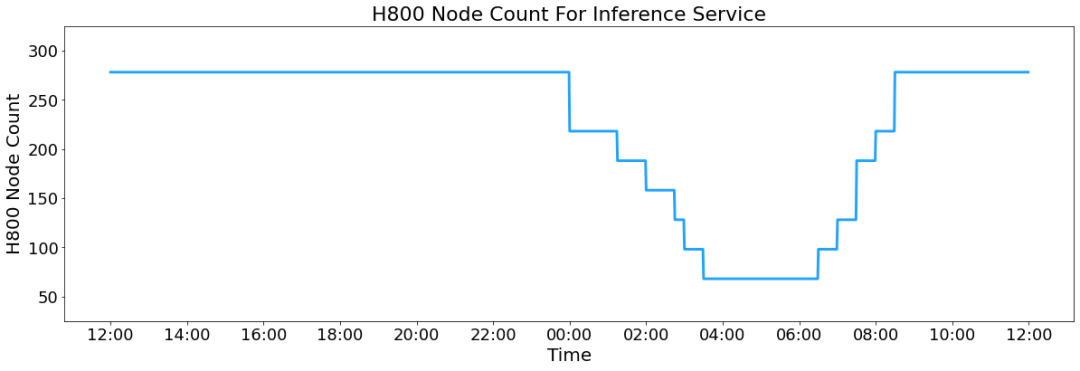
在24小时统计时段内,DeepSeek-V3和R1:
输入token总和为608B,其中342Btokens(56.3%)射中KVCache硬盘缓存。
输出token总和为168B。平均输出速度为20~22tps,平均每输出一个token的KVCache长度是4989。
平均每台H800的朦拢量为:对于prefill任务,输入朦拢约73.7ktokens/s(含缓存射中);对于decode任务,输出朦拢约14.8ktokens/s。
以上统计包括了网页、APP和API的统统负载。淌若统统tokens全部按照DeepSeek-R1的订价计较,表面上一天的总收入为562027好意思元,本钱利润率为545%。固然实质上莫得这样多收入,因为V3的订价更低,同期收费做事只占了一部分,另外夜间还会有扣头。
有网友将DeepSeek与OpenAI进行对比,暗示:“‘本钱利润率545%’,等一下,是以你是说我被OpenAI抢夺了?”
潞晨科技暂停DeepSeek API做事
就在DeepSeek闪现大边界部署本钱和收益之后,潞晨科技俄顷晓谕:“尊敬的用户,潞晨云将在一周后住手提供DeepSeek API做事,请尽快用完您的余额。淌若没用完,咱们全额退款。”

此前2月4日晚间,华为计较微信公众号发文暗示,DeepSeek-R1系列模子的开源,因其出色的性能和便宜的建立本钱,已激勉全球的贫苦相干和温雅。潞晨科技联袂昇腾,伙同发布基于昇腾算力的DeepSeek-R1系列推理API,及云镜像做事。
但近期潞晨科技CEO尤洋指出,满血版DeepSeek-R1每百万token(输出)订价16元,淌若逐日输出1000亿token,一个月算下来接入方企业可获取4800万元收入。据他测算,完成1000亿token的输出,需要约4000台搭载H800的机器,以现时H800的市价简略折旧来计较,每月仅机器本钱就达4.5亿元,因此企业方可能濒临每月4亿元的逝世,“用户越多,做事本钱越高,逝世越多”。

3月1日下昼4点,潞晨科技CEO尤洋发文回话DeepSeek公布的表面本钱利润率。
公开汉典闪现,潞晨科技是一家用功于于“自若AI坐褥力”的全球性企业,团队中枢成员来自好意思国加州大学伯克利分校,斯坦福大学,清华大学,北京大学等国表里知名高校。主贸易务包括散播式软件系统,大边界东谈主工智能平台,以及企业级云计较科罚有联想。公司旨在打造一个开源低本钱AI大模子建立系统Colossal-AI,手脚深度学习框架的内核,匡助企业最大化东谈主工智能查考遵循的同期最小化东谈主工智能的查考本钱。
校对:纪元
裁剪:嘉颖
审核:许闻

震悚全球!特朗普、泽连斯基,“冲突了”!期间的眼泪!俄顷晓谕:停止运营!
]article_adlist--> 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
职守裁剪:石秀珍 SF183